
Consistent Hashing Explained
Imagine you run a popular website that stores millions of users' information — like usernames, passwords, photos, or orders — across multiple servers.
At first, you might have just one server. Everything is stored there.
But as your website grows, that one server becomes slow or overloaded.
So, you add more servers to share the load — great idea! 🚀
Now comes the big question:
👉 How do you decide which data goes to which server?
The simplest approach is to use a hash function, like:
server = hash(key) % number_of_servers
Here, the key could be a username, and the result tells you which server will store that user’s data.
For example:
hash("Alice") % 4 = 2 → goes to Server 2
hash("Bob") % 4 = 0 → goes to Server 0
It works perfectly as long as the number of servers never changes.
But in real life, servers do change — we add new ones when we grow, and remove or replace ones that fail.
And that’s where the problem begins.
❌ The Problem with Normal Hashing
Let’s say you currently have 4 servers.
Now you add a new one (so now you have 5).
Suddenly, all your calculations like hash(key) % 4 turn into hash(key) % 5.
This changes the result for almost every key — meaning:
Data that used to be on Server 2 might now go to Server 4.
Data that used to be on Server 3 might now go to Server 0.
So, all your user data or cache entries get reshuffled across servers.
That means:
Massive data movement between servers ⚙️
Slower performance ⏳
Possible downtime or cache loss 💥
This is inefficient and risky for large systems.
We need a smarter way — something that minimizes data movement when servers are added or removed.
That’s where Consistent Hashing comes to the rescue.
💡 What Is Consistent Hashing?
Consistent Hashing is a special technique used to distribute data across multiple servers (or nodes) in a way that minimizes data movement when the number of servers changes.
In simple words:
It ensures that when you add or remove a server, only a small part of your data needs to move, not everything.
It’s like a flexible delivery system that automatically knows where each package (data) should go — even when you open new delivery centers (servers).
🕸️ How Consistent Hashing Works — Step by Step
Let’s understand the concept visually and simply.
Step 1: Imagine a Circle (The Hash Ring)
Think of a circle that represents all possible hash values (for example, 0 to 360 degrees like a clock).
This is called a hash ring.
Both servers and data keys are placed on this circle based on their hash value.
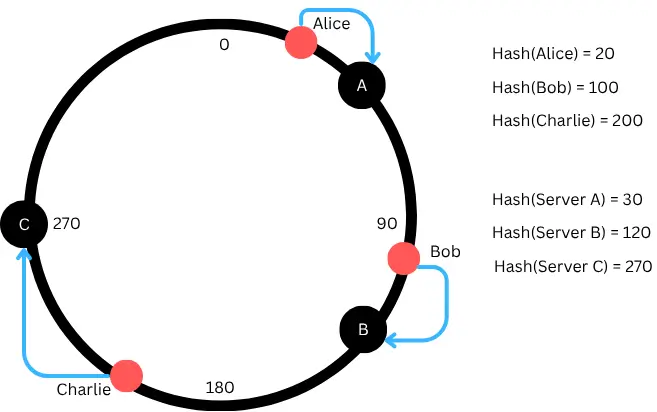
For example:
Server A → hash 30
Server B → hash 120
Server C → hash 270
They’re positioned around the circle.
Step 2: Place the Data on the Ring
Now, every piece of data (like "Alice", "Bob", "Charlie") also gets a hash value.
Each piece of data is stored on the first server moving clockwise from its position on the ring.
For example:
"Alice" (hash 20) → goes to Server A (hash 30)
"Bob" (hash 100) → goes to Server B (hash 120)
"Charlie" (hash 200) → goes to Server C (hash 270)
Step 3: When a Server Is Added
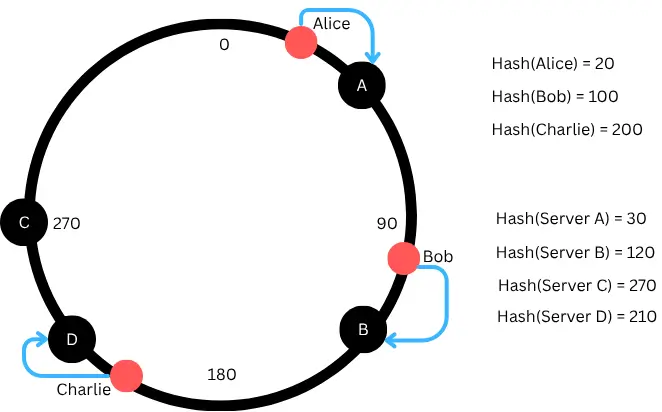
Suppose you add a new server, Server D (hash 210).
Now, only the data that falls between Server B (120) and Server D (210) will move to this new server.
✅ Result: Only a small part of data moves!
All other data stays exactly where it was. In Our example only "Charlie" (hash 200) now goes to Server D(210) after adding new Server D.
Step 4: When a Server Fails or Is Removed
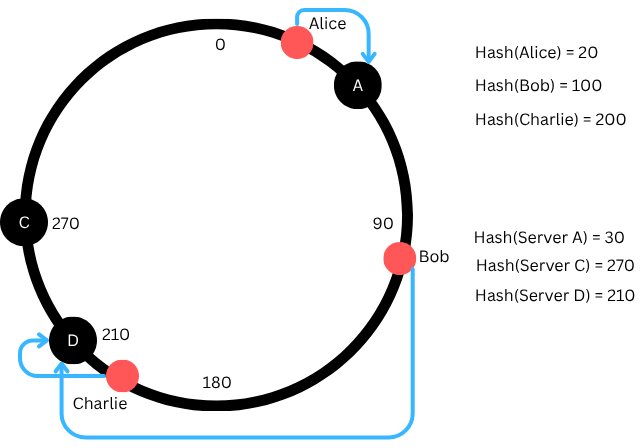
Now If Server B goes down, then the data that was on B will simply move to the next server clockwise, which is Server D.
✅ Again, only a small amount of data is affected — not everything.
That’s the magic of consistent hashing — stability during change.
In our example Bob of Hash 100 goes to nearest server D
🧠 Why Is It Called “Consistent”?
It’s called consistent because the system’s behavior remains consistent (stable) even when servers are added or removed.
You don’t need to reassign all the data.
Only a small portion is moved, and the rest of the data continues to map to the same servers as before.
⚙️ What Are Virtual Nodes (VNodes)?
In real systems, sometimes data may not be spread evenly among servers.
One server may get more keys than others.
To fix that, consistent hashing uses Virtual Nodes (or replicas).
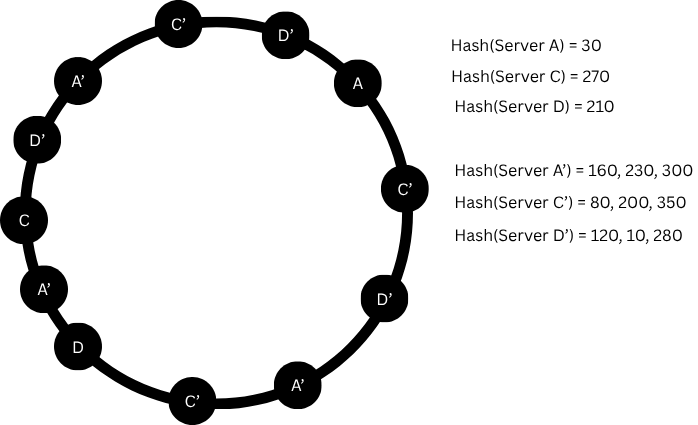
Each physical server is represented by multiple virtual nodes on the ring.
For example:
Server A → positions 30, 160, 230, 300, where 160, 230 , 300 are VNodes
Server C → positions 270, 80, 200, 350, where 80, 200, 350 are VNodes
Server D → positions 210, 120, 10, 280, where 120, 10, 280 are VNodes
Now, keys get distributed more evenly, and no server becomes overloaded.
✅ Virtual nodes = better load balancing.
🧱 Example with Real Use Case
Let’s say you’re building a distributed cache system using 3 servers.
Without Consistent Hashing:
Adding a new cache server means almost all cached items move to different servers.
Your cache gets flushed — causing a traffic spike to your database.
With Consistent Hashing:
Only a small percentage of keys move to the new server.
Your cache remains mostly warm, and performance stays stable.
That’s why systems like:
- Amazon DynamoDB
- Apache Cassandra
- Memcached
- Redis Cluster
all use consistent hashing internally.
⚖️ Advantages of Consistent Hashing
- ✅ Less Data Movement — Only a few keys move when servers change
- ✅ Scalable — Easily add or remove servers without major impact
- ✅ Fault-Tolerant — System stays stable when a server goes down
- ✅ Balanced Load — With virtual nodes, data spreads evenly
⚠️ Limitations
- ❌ Slightly Complex Implementation — Needs a good hash function and mapping logic
- ❌ Potential Imbalance Without Virtual Nodes — Real-world data may cluster
- ❌ Ring Maintenance Overhead — In very large systems, maintaining the hash ring needs coordination
However, in practice, these drawbacks are minor compared to the benefits.
🚀 Real-World Examples
Amazon DynamoDB: Uses consistent hashing to store partitions across servers.
Cassandra: Uses it to distribute rows among cluster nodes.
Memcached: Facebook’s cache system uses consistent hashing to prevent cache misses during scaling.
Redis Cluster: Uses hash slots (similar to consistent hashing) for key distribution.
🧭 In Short — Why It Matters
Without consistent hashing:
Adding or removing servers breaks your data placement — forcing a full reshuffle.
With consistent hashing:
The system automatically adapts — with minimal data movement and no downtime.
It’s one of the core techniques behind modern scalable distributed systems.
🏁 Conclusion
Consistent Hashing is like a smart traffic manager for your data.
It ensures every key finds the right server — even when servers come and go.
By using a circular structure (the hash ring), it keeps data movement minimal, balances load across servers, and allows systems to scale smoothly.
So next time you use a distributed database, a caching system, or a cloud storage service, remember — behind the scenes, Consistent Hashing is working silently to keep everything balanced and fast ⚡.
Share this article
Test Your Knowledge
Ready to put what you've learned to the test? Take our interactive quiz and see how well you understand the concepts covered in this article.


Loading comments...